-
Kafka purgatory (1)개발하면서/타인글보면서 2020. 6. 29. 00:18반응형
4. 그래서 Kafka에서는 어떻게 사용되고 있냐?
DelayedOperation으로 검색하면 다양한 곳에서 사용하는데(Group Coordinator, Replica Manager, ZkAdminManager 등...)
여기서는 Replica Manager 기준으로 알아본다.
broker가 가동되면 Replica manager가 한 개씩 생성되고 Replica Manager에는 역할 별 Purgatory가 존재한다.이때 Partition을 생성하면 ReplicaManager의 Purgatory를 주입해서
아래 그림의 왼쪽은 파티션을 생성할 때 replicaManager의 Purgatory를 delayedOperations로 만들어 주입하는 코드고
오른쪽은 도식화 한것이다.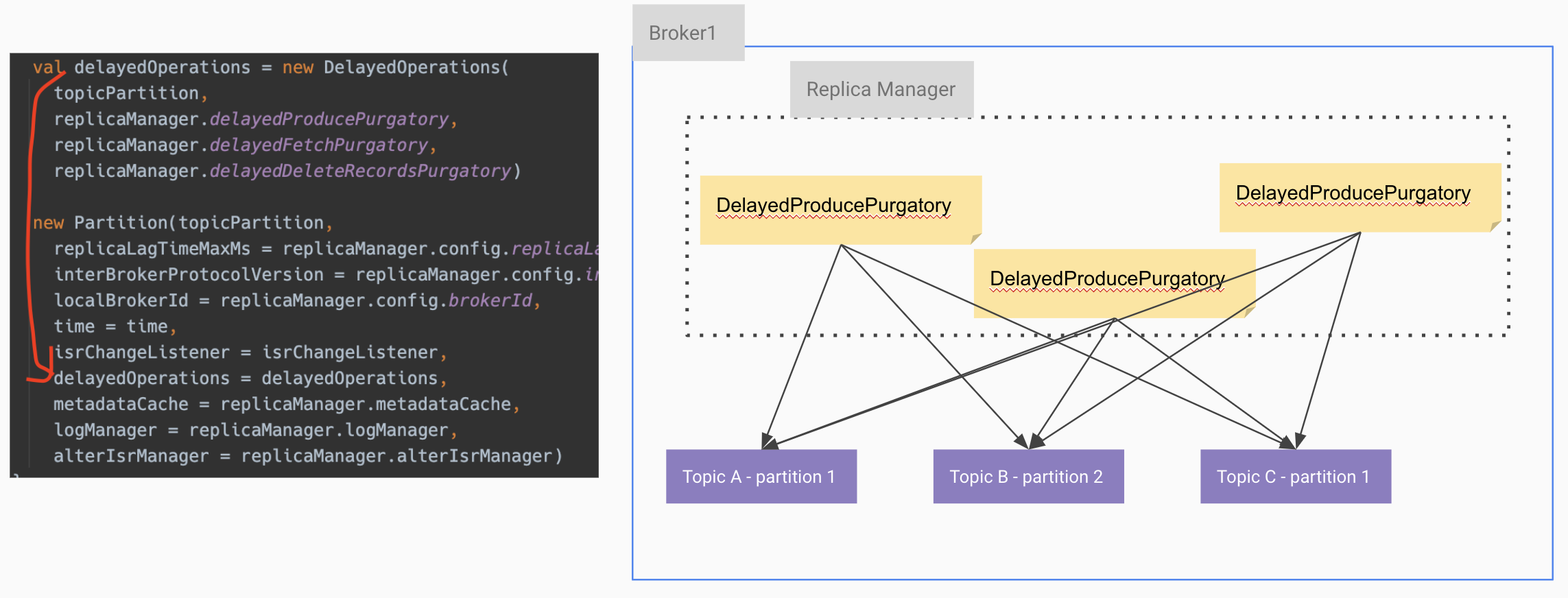
purgatory injection 아래 그림은 xxxPurgatory의 전체 모습을 간단히 그린 것이다.
Timer는 Hierarchical Timing wheel로 변경해서 추가/삭제를 O(m)/O(1)로 처리할 수 있도록 하였다.

그리고 Watcher의 task와 Timer task를 참조하는 형태로 만들어서 Watcher에서 조건을 만족해 삭제가 진행되면
Timer에서 바로 삭제할 수 있도록 하였다.Expire task를 어떻게 구성했길래 Watcher의 task와 Timer의 task를 연결했는지 알아보자.
왼쪽을 보면 지금까지 얘기한 Expire task가 실제 구현된 코드가 있다. 토픽 생성, 리더 투표, 메시지 fetch, 토픽 삭제 등... Delayedxxx
이런 연산은 TimerTask가 scala의 trait로 되어있고 TimerTask를 extends 한 DelayedOperation이 있고
DelayedOperation을 extends 한 Delayedxxx가 있다. 마지막으로 TimerTask의 멤버 변수로 TimerTaskEntry까지!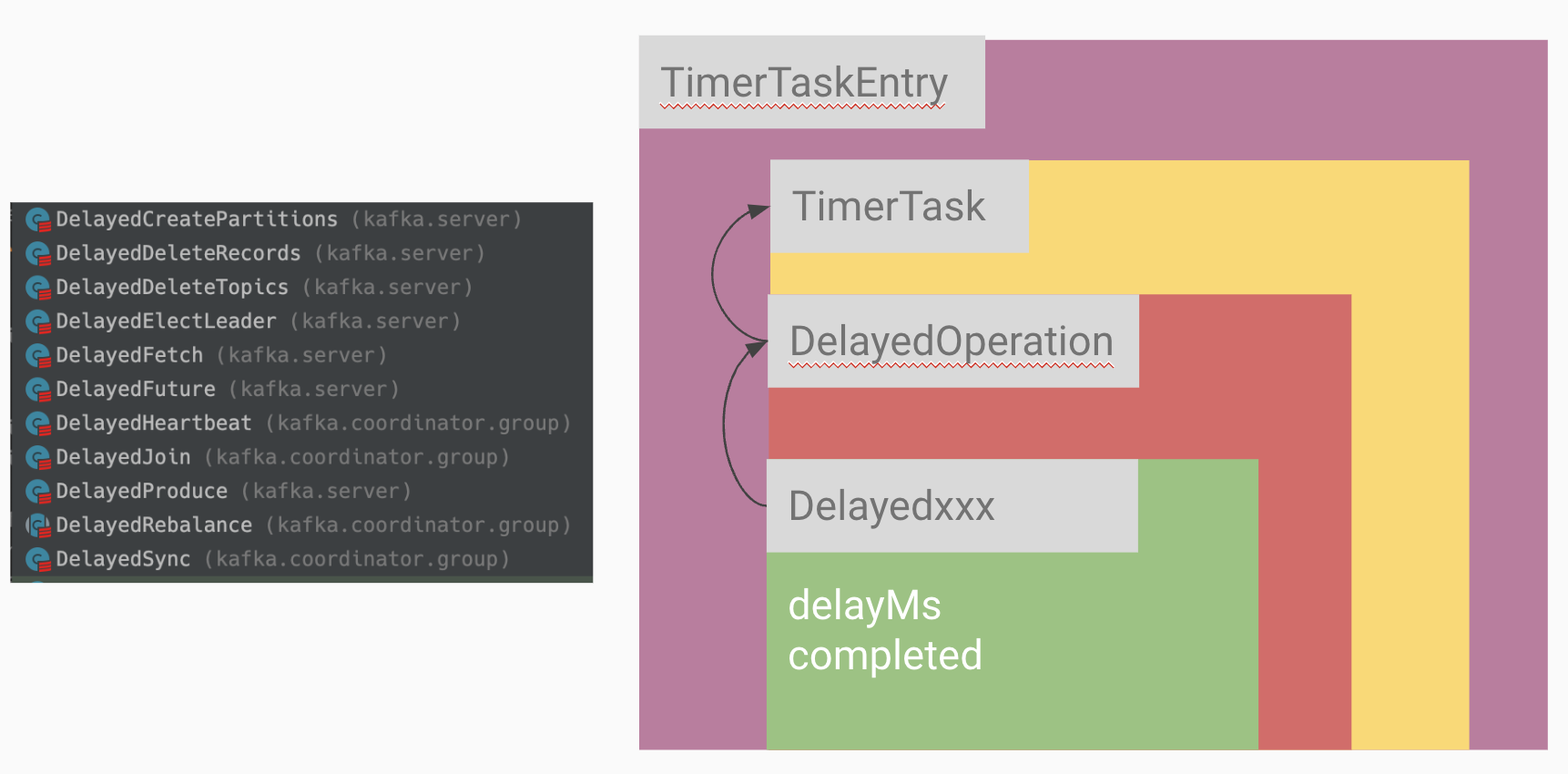
TimerTaskEntry를 이용하여 TimerTask의 양방향 연결 리스트를 만들 수 있다.
Timer의 Expire task가 추가될 때 알맞은 slot 인덱스를 찾고 TimerTaskList 형태로 task가 추가된다.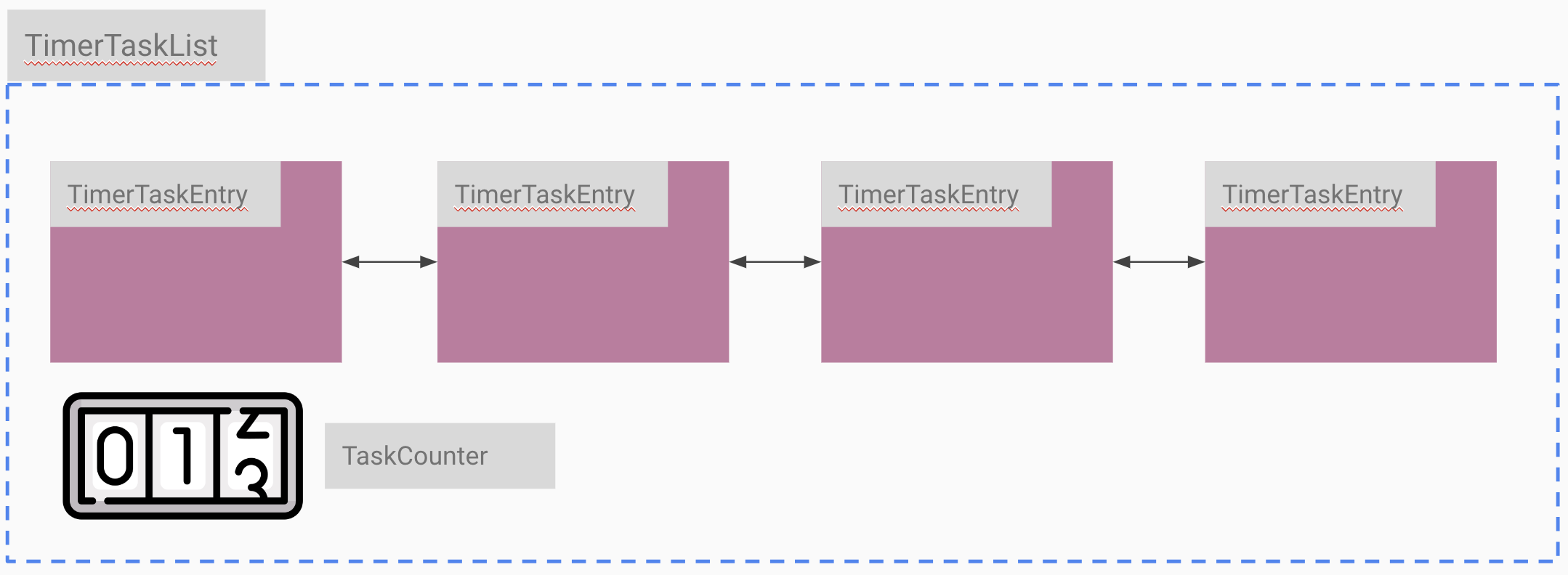
Timer에서 Hierarchical timing wheel이 존재하고 Expire task가 추가되면 적당한 Timing wheel의 적당한 slot에 TimerTaskList에
task가 추가된다. DelayeQueue가 여기도 사용되는데 기존과 다른 점은 task마다 한개씩 추가되는 형태가 아니라 TimerTaskList 단위,
즉 최대 Timing wheel slot 개수만 큼 추가 된다.
이게 가능한 이유는 하나의 TimerTaskList에 존재하는 task들은 해당 level Timing wheel에서 동일한 시간의 expire이기 때문이다.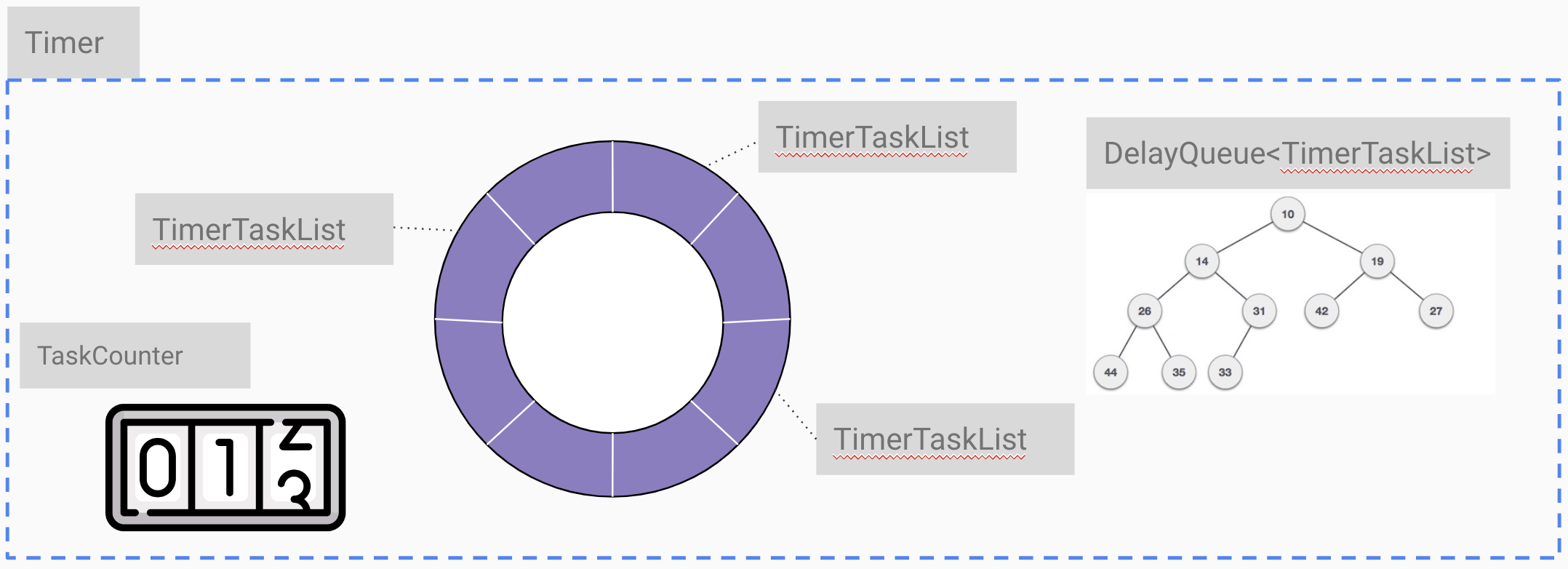
Watcher는 DelayedOpeartion type으로 ConcurrentLinkedQueue 자료구조를 이용하여 task를 저장된다.
배열로 되어있는 WatcherLists와 Map으로 되어있는 WatcherByKey의 value로 ConcurrentLinkedQueue가 연결된 형태다.
"[Topic name]-[Partion Number]" 문자열을 해싱한 값의 WatcherLists.size() 나머지 값으로 WatcherLists의 인덱스를 선택한다.
(주석을 보니 나름 샤딩을 위함이라고 되어있다.)
"[Topic name]-[Partion Number]" 문자열이 WatcherByKey의 키가 되고 값에는 DelayedOperation이 Queue에 추가된다.
Watcher에서 조건이 만족되면 Timer에서 바로 지울 수 있다고 했는데 어떻게 진행되는지 살펴보자.

Watcher에서 조건을 만족한 DelayedOperation이고 이건 TimerTask로 형 변환이 가능하다.
TimerTask에 있는 멤버 변수 TimerTaskEntry를 이용해서 TimerTaskList에서 본인 것만 삭제를 딱!! 하면 두 곳 모두 task 삭제가 된다.반대로 Timer에서 지워진 task는 Watcher에 바로 지우지 않고 Reaper Thread가 주기적으로 실행하면서 조건이 만족되면
정리를 시작한다. 어떤 조건이냐면 Watcher에 등록된 task와 Timer에 등록된 task 개수 차이가 1000(default) 이상이다.오픈 소스를 여러 개 보다 보니 나름 나만의 팁이 있는데 오픈 소스의 특정 기능을 본다고 하면 모든 코드를 파악하려고 하려 하지 말고
내가 궁금한 것을 리스트로 만들고 궁금한 점을 코드와 문서를 통해 알아간다는 마음으로 진행하면 조금 수월해진다.
Kafka Purgatory에서 궁금한 것을 나열하고 어떻게 처리하는지 알아본다. ※ consumer fetch를 예로 진행Q1: fetch.max.wait.ms를 2000으로 하면 Timing Wheel은 겁나 많이 만들어지겠네?
A: 여기서 Hierarchical이 빛을 발한다.
처음 Timing Wheel이 만들어질 때 wheelSize(bucket size)는 20, tickMs 1ms, interval은 20ms의 Wheel이
하나 만들어진다. 이때 fetch.max.wait.ms: 1000 요청이 들어온다면 해당 wheel은 감당할 수 없어
추가 Timing Wheel을 만든다. 바로 아래처럼private[this] val interval = tickMs * wheelSize @volatile private[this] var overflowWheel: TimingWheel = null ... private[this] def addOverflowWheel(): Unit = { synchronized { if (overflowWheel == null) { overflowWheel = new TimingWheel( tickMs = interval, wheelSize = wheelSize, startMs = currentTime, taskCounter = taskCounter, queue ) } } }새로 생성되는 Timing Wheel의 tickMs는 이전 interval을 설정하면서
wheelSize 20, tickMs 20ms, interval 20 * 20ms = 400ms로 생성된다.
아직도 fetch.max.wait.ms 1000 요청은 감당할 수 없으니 추가 Timing Wheel을 만드는데
예상한 것처럼 wheelSize 20, tickMs 400ms, interval 20 * 400ms = 8000ms로 생성이 되고 요청은
8000ms interval Timing Wheel에 저장된다.92초 Expire task가 추가되는 경우 예제 그림

Q2: consumer fetch.max.wait.ms를 2분, fetch.min.bytes를 3으로 설정했을 때 첫 요청 시
새로운 record가 없어서 purgatory에 대기하는 것까지는 이해했다.
그럼 2분 동안 마냥 기다리고 있다가 2분 되면 새로운 record 확인을 하는 건가?
아니면 watcher를 주기적으로 살펴보는 별도의 thread가 있는 건가?A: 생각보다 굉장히 간단하게 구현되어있다. 리더 파티션에 record가 기록되면 Watcher에서 해당 토픽/파티션에
DelayedOperations task들을 한 바퀴 쭉~~ㅋ 돌면서 완료 조건을 만족하는지 체크한다.// appendRecordsToLeader method 마지막에 tryCompleteDelayedRequests 호출 private def tryCompleteDelayedRequests(): Unit = delayedOperations.checkAndCompleteAll() def checkAndCompleteAll(): Unit = { val requestKey = TopicPartitionOperationKey(topicPartition) fetch.checkAndComplete(requestKey) produce.checkAndComplete(requestKey) deleteRecords.checkAndComplete(requestKey) }Q3. consumer에서 fetch 할 때 대기 중인(purgatory에 머물러있는) request는 consumer에서
다시 요청하면 안 될 텐데 어떻게 구현했을까?A: consumer가 broker에게 fetch 요청을 보낼 때 실행되는 함수 sendFetches.
fetch request를 만들기 전에 prepareFetchRequest라는 method로 fetch 요청 보낼 Broker Node_Id -> 토픽/파티션 정보를 조회한다.public synchronized int sendFetches() { Map<Node, FetchSessionHandler.FetchRequestData> fetchRequestMap = prepareFetchRequests(); ... RequestFuture<ClientResponse> future = client.send(fetchTarget, request); // fetch 요청을 보낼 broker node id this.nodesWithPendingFetchRequests.add(entry.getKey().id()); future.addListener(new RequestFutureListener<ClientResponse>() { @Override public void onSuccess(ClientResponse resp) { // 성공해도 nodesWithPendingFetchRequests에서 제거 nodesWithPendingFetchRequests.remove(fetchTarget.id()); } @Override public void onFailure(RuntimeException e) { ... // 실패해도 nodesWithPendingFetchRequests에서 제거 nodesWithPendingFetchRequests.remove(fetchTarget.id()); } }그리고 요청을 보낸 Broker Node_Id를 nodesWithPendingFetchRequests에 저장한다.
다음 sendFetches 할 때 prepareFetchRequests()에서 nodesWithPendingFetchRequests에 있는 Broker에는 요청을 skip 하는
것으로 KafkaConsumer가 구현되어있다.그림으로 간단하게 풀어보면
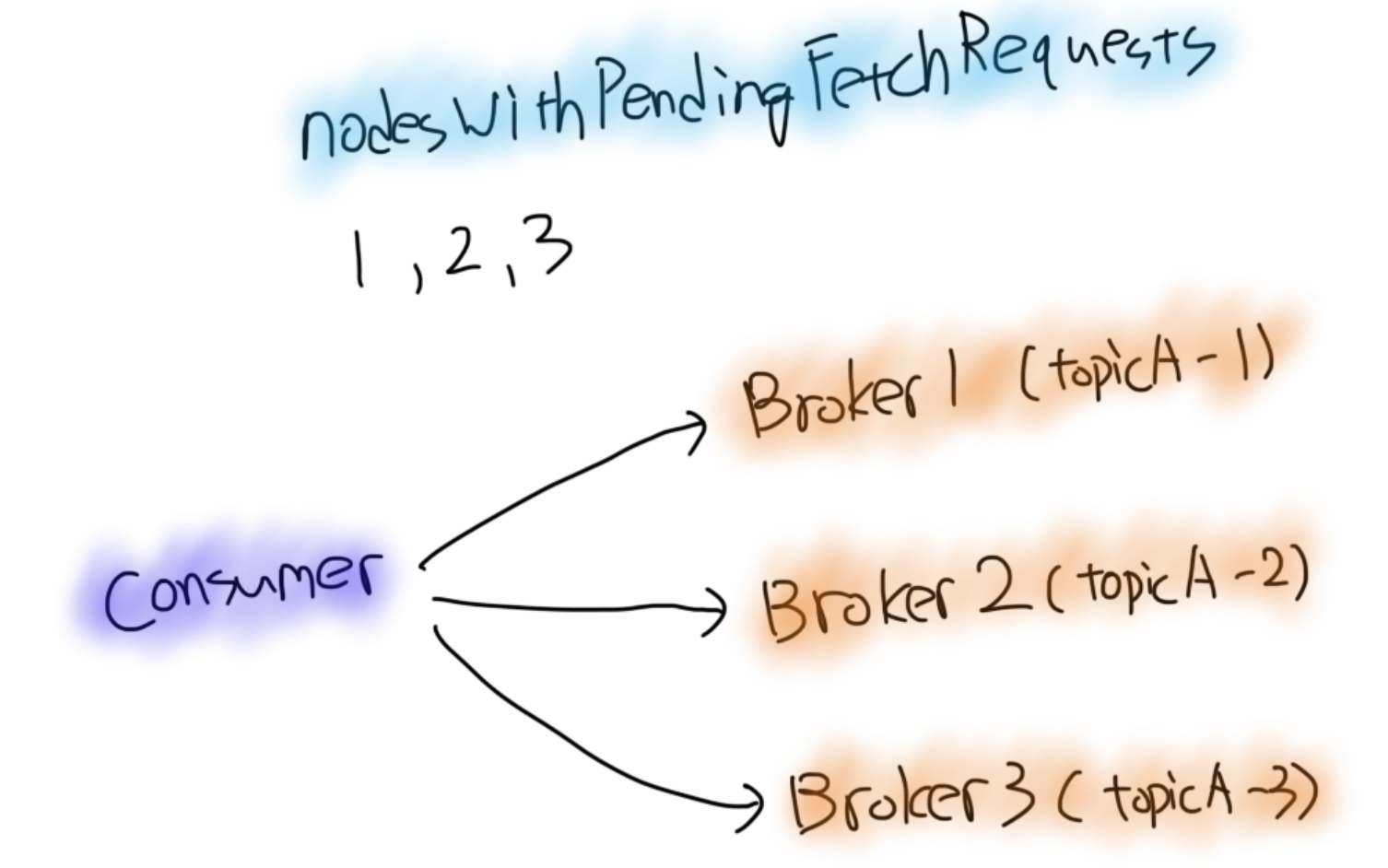
Consumer 하나가 3개 파티션이 있는 TopicA를 subscribe 하고 있고 파티션은 브로커 3개에 골고루 퍼져있다고 가정하면
위에처럼 nodesWithPendingFetchRequests에 1, 2, 3이 저장되고 3개 노드에 요청을 보낸다.
두 개의 Broker는 조건이 만족되어 response가 왔지만 Broker 2는 조건이 만족되지 않아 purgatory에 있는 상태

다음번 fetch 요청할 때는 Broker 2는 건너뛰고 요청을 보낸다.
※ nodesWithPendingFetchRequests를 List 같이 그렸지만 Set이다.5. 내 생각
올해 4월부터 서비스 백엔드 개발을 하기 시작하면서(아무도 안 궁금한 근황 토크) 스케줄러 프로젝트를 보게 됐고,
이때 에버노트 깊숙한 곳에 있던 Kafka purgatory가 생각났다.초년생 때는 이 오픈소스를 싹 다 뜯어봐서 한 분야에 최고가 돼야지!!(지금 생각해보니 뜯어보기만 한다고 최고는 아닌데...;;)
라는 생각이었다면 요새는 지금 맡은 일하면서 마주한 문제들을 오픈소스 플젝에서는 어떻게 해결하고 있는지 파악하자!!
에 무게를 두고 있다.물론 이 생각이 내가 개발에 대한 열정이 줄어서 투자하는 절대 시간이 준 것을 방어하기 위한 핑계일 수도 있지만... 쨋든
Kafka purgatory를 나름 정리해보면
1. Interval이 다른 여러 Timing Wheel을 이용해서 Per-tick 검사가 간단해졌고 긴 시간의 expire도 무리 없이 처리 가능
2. Watcher 체크하는 타이밍이 기가 막히고 (특정 토픽/파티션에 새로운 record가 들어올 때 해당 Watcher만 체크!!)
3. broker에서 대기 중인 요청에 대한 관리도 클라에서 적절하게 잘해주고 있다.
4. Watcher에서 task가 완료되면 Timer에서는 바로 삭제, Timer에서 task 완료(expire)되면 Watcher에서는
바로 삭제하지 않는다. Reaper Thread가 특정 조건을 만족했을 때 Watcher의 모든 task를 순회하면서 정리를 시작한다.아직 완벽하게 이해하지 못했고 그대로 실무에 적용할 수는 없겠지만 손에 익혀두면 써먹을 데가 있을 것 같다.
2022년 2번째 밋업에서 Purgatory 발표를 진행했으니 자료도 참고해주세요.
발표자료
동화책 느낌으로 상상하면서 Purgatory를 하나씩 하나씩 이해하는 걸 예상했는데 생각처럼 안 됐다.
어느순간부터 내가 어디까지 설명해야하나...고민되면서 준비했던 발표 스크립트 하나도 못 봄, 멘붕 옴
다들 귀중한 시간 내서 밋업 참석하셨을텐데 참 미안했다.
발표에서 뾰족한 한 두개가 아니라 넓은 범위를 자세히 전달하려다 보니 잘 안된것 같다. (결국 욕심...)
그리고 굉장히 감사하게 좋은 피드백이 있었는데, 자료에 글씨가 없어서 잠깐만 다른 곳에 신경 쓰면 진도가 나가서
이해가 안 됐다고 했다. 타이슨의 명언이 생각났다.
누구나 그럴싸한 계획이 있다. 처맞기 전까지는...반응형