-
Elasticsearch shard 할당 방식을 정리해보자개발하면서/타인글보면서 2019. 11. 27. 21:13반응형
최근 사내에서 사용하고 있는 Elasticsearch를 별다른 설정 없이 쓰다 보니 종종 인덱스/샤드 관련 문제가 생겨서
shard allocation 관련 학습 필요성이 생겼다.Elasticsearch Shard allocation 공식 문서와 AWS의 shard allocation 문서를 읽고 나름 직역했다.
https://www.elastic.co/guide/en/elasticsearch/reference/7.2/modules-cluster.html
master 노드의 주 역할은 인덱스의 샤드를 데이터 노드에 (고르게) 분배하고 균형을 위해 샤드를 재분배하는것입니다.
샤드 할당하는 4가지 방법과 꿀팁을 소개합니다. 여기서 소개하는 설정 값은 cluster update settings에 나온 방법으로 설정 가능합니다.
- Cluster level shard allocation 샤드 할당과 재분배 설정을 소개합니다.
- Disk-based shard allocation Elasticsearch가 샤드 할당 시 디스크를 고려하는 방법과 설정을 소개합니다.
- Shard allocation awareness 과 Forced awareness 에서는 다른 서버 랙 혹은 다른 존에 샤드를 할당하는 방법을 소개합니다.
- Cluster-level shard allocation filtering 샤드 할당 시 노드 한 개 혹은 그룹으로 묶인 노드들을 포함/제외하는 방법을 소개합니다.
Cluster level shard allocation
샤드 할당은 initial recovery, replica 할당(증설), 재할당, 그리고 노드가 추가/삭제될 때 발생하는데 관련 설정들은 다음과 같습니다.
cluster.routing.allocation.enable
샤드 할당을 허용할 샤드 종류
all, primaries, new_primaries, none (변수명이 너무나 확실해서 자세한 설명은 생략..)
이 세팅은 노드 재시작 시 local primary shard 복구 시에는 해당하지 않습니다.
※ local primaries 란 remote cluster의 primaries가 아닌 것을 말합니다. (remote cluster)예를 들어 primary 샤드를 갖고 있는 노드가 재시작하면 재시작된 노드의 primary 샤드 allocation id와
active인 allocation id를 비교해서 같다면 바로 primary로 즉시 복구합니다.cluster.routing.allocation.node_concurrent_incoming_recoveries
cluster.routing.allocation.node_concurrent_outgoing_recoveries
동시에 샤드 복구를 허용하는 개수, 두 설정 모두 default는 2
incoming은 샤드 rebalance가 아니라면 대부분 replica 샤드이고 outgoing은 샤드 rebalance가 아니라면 대부분 primary 샤드입니다.cluster.routing.rebalance.enable
재분배가 가능한 샤드의 종류. all, primaries, replicas, none
cluster.routing.allocation.allow_rebalance
샤드 재분배를 허용하는 경우.
always
indicdes_primaries_active: 모든 primary 샤드가 클러스터에 할당된 경우
indices_all_active(default): 모든 샤드가 할당된 경우cluster.routing.allocation.cluster_concurrent_rebalance
동시에 재분배할 샤드 갯수
Shard balancing heuristics
아래 설정 값은 각 샤드를 할당할 노드를 선택할 때 위에 소개한 설정과 함께 사용됩니다.
위 3개의 rebalancing settings값에서(rebalance 문자가 있는 설정 값) 허용된 rebalance 작업이 더 이상 balance.threshold 값보다
높일 수 없다고 판단되면 해당 클러스터는 균형을 이루었다고 판단하고 재분배가 안 일어날 수도 있습니다.cluster.routing.allocation.balance.shard
전체 샤드 개수 중 해당 노드에 할당된 샤드 개수의 weight factor
default는 0.45f, 값을 높일수록 노드당 갖고 있는 샤드 개수가 비슷해집니다.cluster.routing.allocation.balance.index
특정 노드에 할당된 인덱스 당 샤드 개수의 weight factor
default는 0.55f, 값을 높일수록 노드당 갖고 있는 인덱스 개수가 비슷해집니다.cluster.routing.allocation.balance.threshold
재분배가 일어날 최솟값
default는 1.0f 값을 높일수록 재분배에 덜 민감하게 동작합니다.노드마다 가중치 계산하고 threshold
balancing algorithm에 의해 재분배를 하려고 해도 forced awareness, allocation filtering에 의해 재분배가 일어나지 않을 수도 있습니다
Disk-based shard allocation
노드에 사용 가능한 디스크를 고려해서 샤드를 할당할 수도 있습니다.
cluster.routing.allocation.disk.watermark.low
샤드 할당 시 고려할 disk low watermark. default 85%
예를 들어 85%로 설정하면 디스크 사용률이 85%인 노드에는 샤드 할당을 하지 않습니다.
이 설정은 새로 생기는 인덱스의 primary 샤드엔 적용되지 않습니다.
값을 비율로 할 수도 할수 있고 (ex: 85%) 절대값으로도(500mb) 할수 있습니다.
비율로 할 때는 사용량을 의미하고, 절대값으로 할때는 남는 공간을 의미합니다.
cluster.routing.allocation.disk.watermark.high
샤드 할당 시 고려할 disk high watermark. default 90%
해당 값을 90%로 설정 시 90% 이상 사용하는 노드가 생기면 샤드 이동을 시도합니다. 이 설정은 모든 샤드에 해당합니다.
cluster.routing.allocation.disk.watermark.flood_stage
넘치는(?) 단계로 판단하는 watermark, default 95%
A 노드의 디스크 사용률이 95%가 넘으면 A노드에 할당된 샤드의 인덱스들은(한 개의 샤드여도) read-only index block이 됩니다.
인덱싱이 가능한 디스크 공간이 생기면(수동으로) 수동으로 index block 설정을 수동으로 해제해야 합니다.https://www.elastic.co/guide/en/elasticsearch/reference/master/index-modules.html
read_only, read_only_allow_delete block 설정된 인덱스마다 들어가서 수동으로 해제
PUT your_index_name/_settings { "index": { "blocks": { "read_only_allow_delete": "false" } } }위 3개의 설정 값은 비율과 절댓값을 섞어 쓸 수 없습니다. (low watermark는 85%, high watermark 500mb 할 수 없다는 얘기)
내부적으로 low < high, high < flood_stage를 검사하기 때문입니다.cluster.info.update.interval
각 노드의 디스크 사용량 정보 업데이트 간격, default 30s
cluster.routing.allocation.disk.include_relocations
노드의 디스크 사용량을 계산할 때 노드의 재배치 중인 샤드 고려 여부, default true
재배치 중인 샤드의 크기를 고려한다는 의미는
한 샤드의 재배치가 90% 정도 진행 중일 때 디스크 사용량을 조회하면 이미 재배치가 완료된 것처럼 디스크 사용량이 계산됩니다.
https://www.elastic.co/guide/en/elasticsearch/reference/current/allocation-awareness.html
Shard allocation awareness
물리적인 거리를 고려해서 shard 할당할 수 있습니다. 'rack_id'와 'zone' attribute를 이용할 수 있습니다.
attribute 값의 개수만큼 샤드를 복사합니다.
Forced awareness
shard allocation awareness 기능을 이용하여 근거리에 샤드를 구성할 수 있습니다.
※ 전 세계에 서비스가 되는데 동일한 데이터 조회가 필요한 경우에 쓰임이 많을 것 같다.
Cluster-level shard allocation filtering
특정 노드를 shutdown 시키려고 할 때 해당 기능을 이용하면 좋습니다.
filtering 할 수 있는 attribute는 node name, host IP, publish IP, IP(host or publish IP), hostname, node id가 있습니다.
자주 나오는 숙어 take ~ into account 가 있었다. 갑자기 계정?? 청구서??? 뭐지??? 했지만
~를 고려하다 라는 뜻으로 consider과 비슷한 느낌이다.
https://aws.amazon.com/blogs/opensource/open-distro-elasticsearch-shard-allocation/
최적의 샤딩은 균일한 리소스를 갖고 모든 요청은 샤드로 구성된 모든 노드로 분배되고 CPU, RAM, Disk 및 Network 리소스를 균등하게 사용하는 것을 말합니다.
하지만 현실은 다르죠... 샤드 분배가 한쪽으로 몰리면 CPU, RAM, Disk 및 Network 리소스 사용도 균등하게 되지 않습니다.
예를 들어 3개의 인덱스가 있고 파란 네모 인덱스는 2개 노드에 할당, 원/노란 네모는 4개 노드에 할당됐다고 하겠습니다.
파랑 인덱스는 다른 두 인덱스보다 10배 많은 트래픽과 크기라고 하면 다른 네 개의 노드 스펙보다 10배 좋은 노드를 세팅해야 할 겁니다.
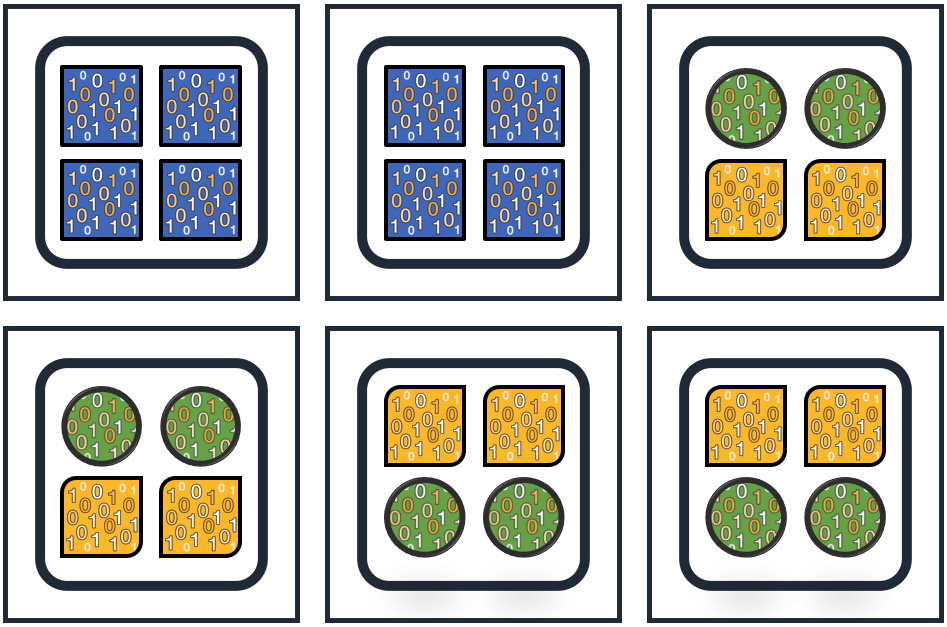
인덱스 할당이 균일해야 하는데 Elasticsearch에서는 어떻게 풀었는지 알아보겠습니다.
Elasticsearch에서 샤드 할당을 책임지는 ShardsAllocator interface가 있습니다.
어떠한 이유로 unassigned 샤드가 생기면 ShardAllocator가 unassigned 샤드를 클러스터 내 어떤 노드에 할당할지 결정합니다.
아래 같은 상황이 발생하면 ShardAllocator가 동작합니다.
engaged to 약속하다, 계약하다, 보증하다, 예약하다, 채우다, 끌어들이다, 관여하다, 착수하다
인덱스 생성 시 - 인덱스가 생성되거나 snapshot으로부터 색인을 복구할 때 ShardAllocator는 샤드를 어디에 할당할지 결정합니다.
사용자가 replica 개수를 늘릴 때에도 동작을 합니다.
노드 장애 시 - 노드 장애로 클러스터에서 노드가 빠지면 ShardAllocator가 동작합니다.
실패한 노드에 있었던 샤드들을 어디에 위치시킬지 결정합니다.클러스터 노드 개수 변경 시 - 클러스터에 노드를 추가/제거하면 ShardAllocator가 동작합니다.
디스크 high water mark 달성 시 - 디스크 사용량이 high water mark(default 90%)에 도달하면
ShardAllocator가 high water mark에 도달한 노드에 존재하는 샤드들을 다른 곳으로 옮기기 위해 동작합니다.수동 리발란스 - 사용자가 클러스터의 균형을 위해 reroute API를 사용하면 ShardAllocator가 동작을 합니다. https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster-reroute.html
클러스터/인덱스 설정에 따른 이동 - 샤드 이동과 관련된 클러스터 혹은 인덱스의 설정 값이 변경되면 동작합니다. https://www.elastic.co/guide/en/elasticsearch/reference/7.2/allocation-awareness.html, https://www.elastic.co/guide/en/elasticsearch/reference/7.2/allocation-filtering.html
샤드 할당 전략은 어떤 샤드를 할당한 것인지, 어떤 노드로 할당할 것인지의 두 가지 문제로 나뉠 수 있습니다.
Elasticsearch에서는 default로 BalancedShardAllocator에 구현을 하였고 세 가지 역할을 합니다.
unassigned 샤드의 할당, 샤드 이동, 그리고 재할당. 세 개의 기능들은 위에서 언급한 두 가지 문제를 해결하기 위해
어떤 노드에 샤드 할당할지, 한 노드에서 다른 노드로 옮길지 혹은 그대로 둘지 결정합니다.클러스터 상태 변경이 있을 때 Elasticsearch에서 reroute라고 불리는 전체 배치 작업이 호출됩니다.
노드 선택
Elasticsearch는 Allocation Decider의 처리를 통해 샤드 할당 가능한 후보 노드 목록을 가져옵니다.
후보 노드 목록은 샤드 및 노드의 샤드 할당 상태에 따라 달라집니다. 특정 샤드에 대해서 모든 노드가 후보 군이 될 수 없습니다.
예를 들어 replica 샤드를 primary 샤드와 같은 노드에 할당하지 않는다거나 디스크가 꽉 차서 샤드 할당을
더 이상 할 수 없는 경우입니다.Elasticsearch는 샤드 할당 시 탐욕적인 방법으로 합니다.
이것은 전체적으로 최적화되기를 추구하면서 지역적으로(locally) 최적의 결정을 합니다.노드의 자격 판단은 가중치 함수로 추상화해서 현재 가장 적합하다고 판단된 노드에 샤드 할당이 됩니다.
가중치 함수는 어떤 인자를 전달하면 노드의 샤드 가중치를 리턴하는 수학 함수라고 생각하시면 됩니다.
샤드 할당에 가장 적합한 노드는 가중치가 가장 적은 노드입니다.AllocateUnassigned
reroute가 실행되면 가장 먼저 실행되는 연산은 allocateUnassigned 입니다.
인덱스가 생성되면 샤드는(primary, replica 모두) unassinged입니다. 노드가 클러스터에서 떨어지면 해당 노드에 할당된 샤드는 유실됩니다.
primary 샤드가 유실됐다면 replica가 primary로 승격되고 replica 샤드는 unassigned 상태로 됩니다.allocateUnassigned의 BalancedShardAllocator에서 모든 unassigned 샤드를 순회하면서
샤드 할당에 적합한 후보 노드"들"을 찾은 후(Allocation Deciders) 가장 작은 가중치의 노드를 선택합니다.
unassigned 샤드 할당 시 노드 고를 때 Elasticsearch는 순서가 있습니다. primary 샤드를 먼저 선택하는데
다른 인덱스 primary 샤드 할당하기 전 하나의 인덱스의 모든 primary 샤드를 할당합니다.인덱스 선택할 때는 인덱스 명과 index settings의 우선순위 값을 기반으로 비교합니다. (PriorityComparator 참조)
이 방법은 Elasticsearch가 많은 인덱스의 샤드가 부분적으로 assigned 상태로 되기보다는 가능한 많은 인덱스의 primary 샤드가
assigned로 되게 합니다.
Elasticsearch의 모든 primary 샤드가 assigned로 되면, 각 인덱스의 첫 번째 replica 샤드를 할당하고
그다음 각 인덱스의 두 번째 replica 샤드를 할당합니다. and so on...샤드 이동
Elasticsearch cluster를 scale down 하는 경우를 생각해보겠습니다.
미국의 블랙 프라이 데이나 중국의 광군제를 대비해 scale out을 했다가 시즌이 끝나면 다시 평소에 트래픽에 맞는 클러스터로 복귀해야 합니다.
이때 여러분은 primary, replica 샤드를 갖고 있는 노드를 내릴 건데 이때 약간의 데이터 유실이 있을 수도 있습니다.
좀 더 좋은 방법은 노드를 바로 삭제하기보다는 exclude filter를 사용하여 모든 샤드가 해당 노드에서 없어지길 기다렸다가 끝났을 때 노드 삭제하는 것입니다.
특정 노드의 디스크가 꽉 차서 샤드 이동으로 저장 공간을 확보해야할할 경우도 있습니다.
allocateUnassigned()가 완료된 직 후에 moveShards()가 실행되어 처리됩니다.
샤드 이동은 클러스터 내에 있는 모든 샤드를 순회하면서 현재 노드에 남아 있을지 말지(can remain) 체크합니다.
이동이 필요하다고 판단되면 적합한 노드 후보군 중에(Allocation Deciders) 가중치가 가장 노드를 선택합니다.
이 노드를 target node라고 부릅니다. 샤드 할당은 현재 노드에서 target node로 이뤄집니다.
moveShards() 연산은 STARTED 상태인 샤드에만 적용되고 다른 상태인 경우 건너뜁니다.
전체 노드에서 균형 있게 샤드를 이동하기 위해 moveShards() 연산은 nodeInterleavedShardIterator를 사용합니다.
이 iterator는 노드에서 너비 우선 순회로 각 노드에서 한 개의 샤드를 고르고, 다음 샤드를 고르는 걸 반복합니다.
그래서 모든 노드의 모든 샤드는 move 관련해서만 평가됩니다. 다른 평가는 하지 않아요.
샤드 리발란스
클러스터가 한계치에 도달했다면 여러분은 scale out을 결정할 겁니다.
Elasticsearch는 더 나은 분산처리를 위해 자동으로 해당 노드를 발견하고 샤드 재할당을 합니다.
노드 추가/삭제 시 항상 샤드 이동이 필요한 건 아닙니다.
※ 노드가 갖고 있는 샤드의 수가 굉장히 적은데 scaleout 대비용으로 노드를 추가한 경우
Elasticsearch는 shard allocator의 가중치 함수를 이용해서 리발란스를 결정합니다.
현재 노드에 할당된 샤드 정보가 주어지면 가중치 함수는 해당 노드의 샤드 가중치 점수를 계산해줍니다.
높은 가중치를 가진 노드는 낮은 가중치를 가진 노드보다 샤드 할당에 적합하지 않은 것입니다.
다른 노드 간에 가중치를 비교해서 Elasticsearch는 분산처리 개선을 위해 리발란스를 할지 말지 결정합니다.
리발란스 결정을 위해서 Elasticsearch는 각 노드의 각 인덱스의 가중치를 계산하고, 해당 인덱스의 최소/최대의 차이를 구합니다.
(Elasticsearch 내에서 인덱스의 각 샤드도 동일하게 계산되기 때문에 index level로 계산을 합니다.)
※ 아마 샤드로 하면 연산이 늘어나니 비슷한 느낌의 인덱스 레벨로 계산한다~ 뭐 그런 내용인 듯)그런 다음 불균형이 심한 인덱스부터 리발란스를 시작합니다.
샤드 이동은 무거운 연산입니다.
실제로 샤드 이동을 하기 전에 이동 하기 전과 후의 가중치를 계산해서 샤드 이동이 클러스터 균형에 더 좋아지는 경우에만 샤드 이동이 이뤄집니다.
결국 리발란스는 최적화 문제입니다.
임계값을 넘어서 샤드 이동 비용이 가중치 균형의 이점보다 훨씬 중요합니다. (임계값은 차치하더라도 샤드 이동은 보수적으로 해야 한다는 얘기인 듯)임계값이 고정 값으로 있고 dynamic 설정으로 값을 변경할 수 있습니다.
cluster.routing.allocation.balance.threshold https://www.elastic.co/guide/en/elasticsearch/reference/current/shards-allocation.html#_shard_balancing_heuristics
인덱스의 delta가 임계값보다 작다면 인덱스는 리발란스를 고려합니다.
결론
Elasticsearch에서 샤드 할당과 샤드 균형 결정하는 방법에 대해 다뤘습니다.
reroute의 실행은 unassigned 샤드의 할당, 현재 노드에서 이동이 필요한 샤드를 이동하고, 가능하다면 샤드 리발란스 하는 과정을 거칩니다.나름 정리
특정 조건에서 ShardAllocator가 발생
어떠한 이유로 할당되지 않는 샤드가 어떤 과정을 통해 할당되는지 알아봤다.
할당 가능한 노드를 선택하는 방법과 노드의 상태로 인해 샤드 이동이 필요한 경우 결정 과정을 알아봤다.
샤드 이동은 STARTED 상태일 때만 일어난다.
리발란스는 생각보다 쉽게 일어나지 않는다. 정말 최악일 때만 일어날 듯
https://www.elastic.co/kr/blog/how-many-shards-should-i-have-in-my-elasticsearch-cluster 를 보면 샤드 하나의 크기는
20~40GB, 최대 50GB로 하라고 추천하고 있다.하지만 크기만 생각해서 샤드 하나를 세팅하면 ingest 속도가 줄고 이는 곧 데이터 반영이 실시간으로 되지 않는것을 뜻한다.
정답은 없으니 본인이 처한 상황에 맞게 하면 좋을것 같다.우선 ingest 속도에 맞게 샤드 갯수 세팅하고 나중에 데이터 안 들어올때 shrink 하는것 테스트 해봐야겠다.
(Roll Over도, X-pack 기능인 Roll up 도)반응형