-
Kafka의 Sticky Partitioner 살펴보기개발하면서/타인글보면서 2020. 1. 18. 13:55반응형
Kafka Broker(server)에 메시지를 주고받는 client 역할을 하는 Kafka Producer / Consumer 중 Producer의
성능 개선 기능이 있어 살펴보려고 한다.
ref url: KIP-480, Apache Kafka Producer improvements Sticky Partitioner[Confluent Blog]Kafka Producer의 메시지 전송 방법
두 부분으로 나뉘어 있다.
사용자 코드에서 send()를 실행하면 토픽, 파티션별 record를 모아 놓는(record batch) Accumulator
Accumulator에 쌓인 record batch를 가져와서 Kafka Broker에 전송하는 작업을 쉼 없이 하는 Network thread
[2.4 코드를 보는데 클래스명이 Sender로 바꼈네요. 하지만 편의상(?) Network Thread 진행하겠습니다 ㅎ]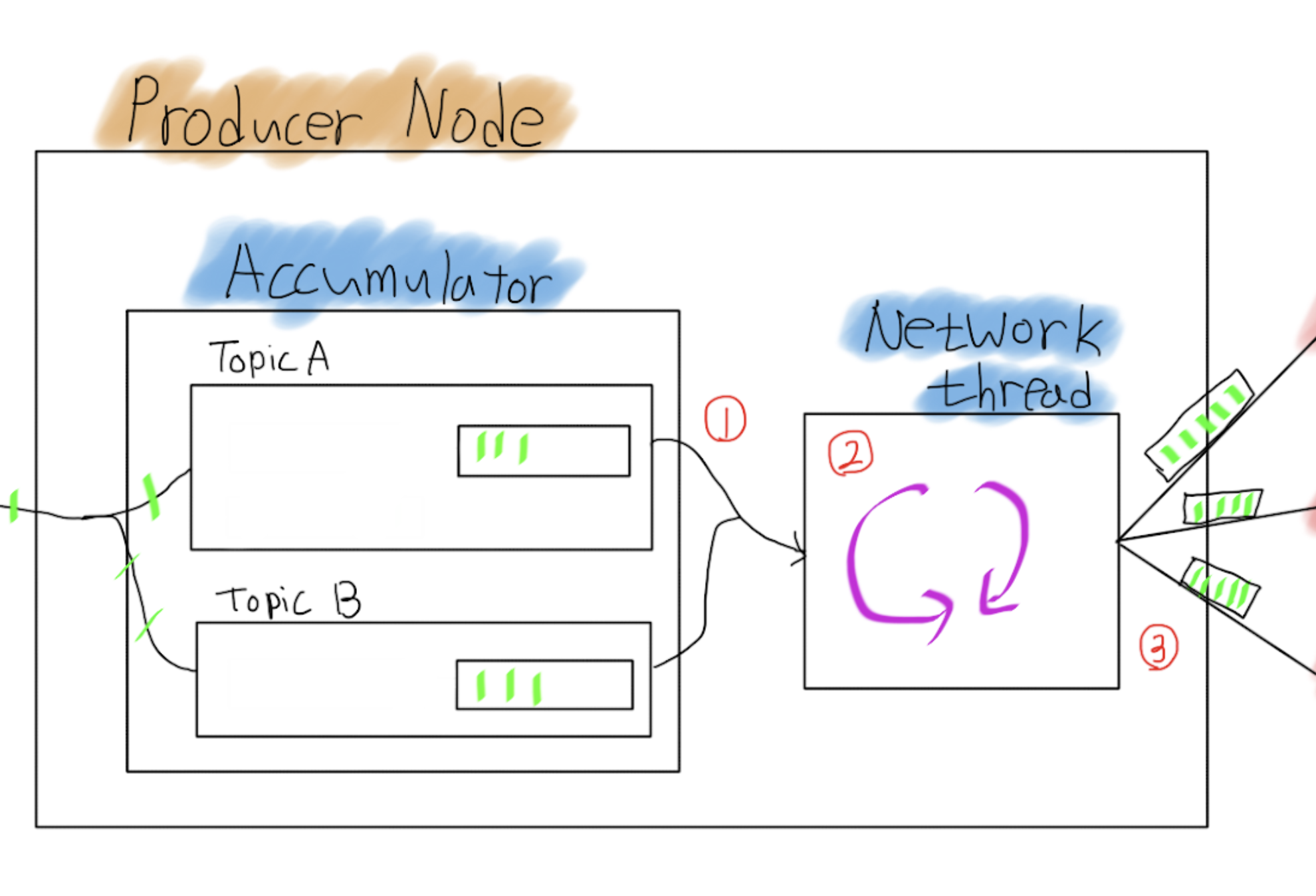
위 그림에 야광색 선 하나를 record로 보고 Accumulator에 record를 감싸고 있는 네모 하나를 record batch라 부르며
record batch는 producer 설정 중 batch.size로 설정 가능하다.
Network thread가 Broker로 전송하는 속도보다 Accumulator에 쌓이는 속도가 더 빠르다면 record batch는
계속 추가되고 전체 record batch 크기가 buffer.memory 만큼 쌓이게 되면 KafkaProducer.send 함수는 블락이 되고
max.block.ms 시간이 넘어가면 exception이 발생한다.더보기buffer.memory: The total bytes of memory the producer can use to buffer records waiting to be sent to the server. If records are sent faster than they can be delivered to the server the producer will block for max.block.ms after which it will throw an exception.
Network Thread는 아래 1, 2, 3 작업을 쉴~~ 틈없이 진행한다. (내가 아는 범위에는) 한 가지 경우만 제외하고...
- 현재 Kafka Broker 상태를 확인해서 보낼수 있는 토픽/파티션 목록을 정리한다.
그리고 Accumulator 에 쌓인 record batch를 가져오는데 이때 가져올 수 최대 크기는 파티션당 max.request.size 만큼이다. - 가져온 record batch를 Kafka Broker node.id 기준으로 정리한다.
예를 들어 Kafka Broker 1번은 Topic A의 1, 3, 4 리더 파티션 그리고 Topic B의 2, 5 리더 파티션이라고 하면
Map(1 -> Topic A의 1, 3, 4 record batch와 Topic B의 2, 5 record batch) 가 된다. - 정리된 데이터를 전송!!
더보기max.request.size: The maximum size of a request in bytes. This setting will limit the number of record batches the producer will send in a single request to avoid sending huge requests. This is also effectively a cap on the maximum record batch size. Note that the server has its own cap on record batch size which may be different from this.
linger.ms을 0 이상의 값을 주면 Network Thread가 Accumulator에서 바로 record batch를 가져가지 않고 기다린다.
대기 시간이 있으므로 record batch가 채워지지만 그만큼 처리 속도는 감소한다.그럼 record batch를 꽉꽉 채워서 보내면 좋은 이유는 어떤건가?
적은 패킷 개수, header 같은 메타 정보를 파싱 하는 연산이 줄어든다는 장점도 있는 반면
실제 반영되는데 시간이 걸리고(Availability 저하?) 전송 실패 시 재전송할 때 커다란 패킷을 다시 보내야 하는 단점도 있다.또한 Broker에 저장 시 아래와 같이 저장이 되는데 한 번에 보낼 때 뭉탱이로 보내면 XXXX.index의 범위가 넓어지므로
시간, Offset 검색 시 보다 빠르게 할 수 있는 장점도 있다.※ 000.index에서 offset:0, position: 0은 메시지 한건만 저장된 경우이고 offset: 1, posititon: 28은 최소 메시지 3건 이상 보낸 경우

기존 Default Partitioner
record을 몇 번째 partiton으로 할지 결정하는 기능을 하는 Partitioner 인터페이스가 있는데
record의 key가 없으면 Round Robin으로 결정, key가 존재하면 hash값의 modular 파티션 개수로 결정을 한다.단순하고 깔끔하지만 메시지 쌓이는 속도가 많지 않다면 아래 그림 왼쪽처럼 record batch를 꽉꽉 채우지 못하고 보내진다.
그래서 나온 Sticky Partition 두둥!! (아래 그림 오른쪽)
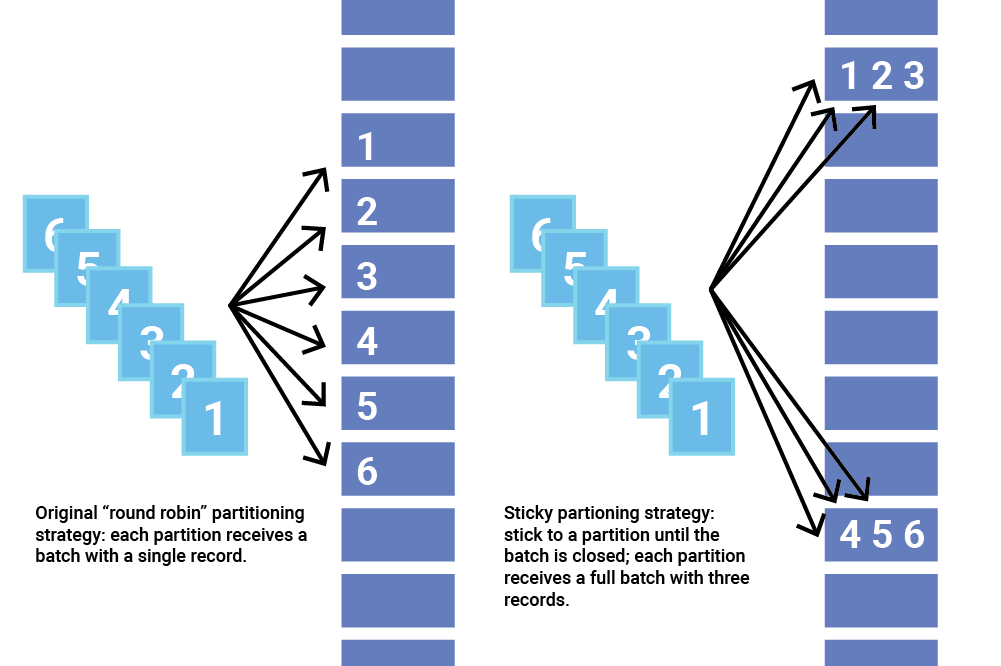
출처: https://www.confluent.io/blog/apache-kafka-producer-improvements-sticky-partitioner Sticky Partitioner
record를 고르게 보내지 말고 이번에 보낼 때는 이쪽, 다음에는 저쪽으로 보내서 record batch를 꽉 채워서 보내자는 게 주 내용이다.
어떻게 구현했는지 간단히 살펴보면,
Partitioner 인터페이스에 onNewBatch라는 default method가 추가되었고 KafkaProducer 코드가 onNewBatch method를
호출하는 타이밍은 다음과 같다. ※ doSend method의 일부 코드// Accumulator에 record를 쌓았는데 RecordAccumulator.RecordAppendResult result = accumulator.append(...); // record batch 가득차서 Accumulator에 쌓지 못한경우 result.abortForNewBatch = true if (result.abortForNewBatch) { int prevPartition = partition; // 이때 onNewBatch method 호출!!!!!! partitioner.onNewBatch(record.topic(), cluster, prevPartition); ... // 다시 append 실행, 이때 record batch 새로 만들고 쌓는 작업을 한다. result = accumulator.append(...); }
Sticky Partitioner는 StickyPartitionCache을 멤버 변수로 갖고 onNewBatch에서 해당 케시를 갱신(?) 하는 method를 호출한다.
record의 partition을 구할때 StickyPartitionCache에서 토픽 단위로 조회한다.StickyPartitionCache는 Map(TopicName -> Partition Number)를 멤버 변수로 갖고
갱신(?) 하는 method가 호출될때 랜덤하지만 균등한(?) Partition Number를 구해서 Map 정보를 갱신한다.
즉 StickyPartitioner를 이용하면 recordBatch에 있는 모든 record는 동일한 partition으로 할당된다. (key가 null인 경우)Sticky Partitioner 적용했을 때 다양한 결과
3 Producers, 16 파티션, 1000 msg/sec 일 때 Round Robin partitioner에 비해 1.5배 빠르다.
심지어 CPU used도 줄었다!! (Broker와 Producer가 같은 서버에 존재)
linger.ms를 1초로 줬을 때는 최대 5배 차이가 난다. Sticky Partitioner의 장점을 너무 잘 보여주기 위한 실험 같지만...linger.ms를 1 이상인 값을 설정하면 Network thread가 대기하지만 batch.size만큼 채워지면 Network thread가
더이상 기다리지 않고 전송을 시작한다. linger.ms를 효율적으로 쓸수 있다는 점에서 괜찮게 본다.더보기This setting gives the upper bound on the delay for batching: once we get batch.size worth of records for a partition it will be sent immediately regardless of this setting, however if we have fewer than this many bytes accumulated for this partition we will 'linger' for the specified time waiting for more records to show up.
key가 있는 record 테스트는 큰 차이 없다.
마무리
파티션 별 순서가 중요하지 않다면 key는 null로 세팅하고 Sticky Partitioner를 사용하면 좋을 것 같다.
호환성은 문제없다고 한다. Producer 코드 변경만 있으므로 Kafka Broker가 1.X여도 적용할 수 있을 것 같다. (이것도 뇌피셜)Java 인터페이스의 default method는 간단한 예시와 말로만 들었지 이렇게 큰 프로젝트에 적용된걸 보니 재밌다.
설명에 첨부된 스샷들은 2019년 Kafka 컨퍼런스에서 발표한 자료입니다. 관심 있는 분들은 한번 보셔요. ㅎ
https://docs.google.com/presentation/d/1byzstmjeVAvn_w5_n-9y1BLutFZUknCqZDfgbKff71c/edit?usp=sharing
반응형 - 현재 Kafka Broker 상태를 확인해서 보낼수 있는 토픽/파티션 목록을 정리한다.