-
if(kakaoAI)2024 day3 시청 및 정리 ... 백엔드개발하면서/타인글보면서 2024. 11. 11. 12:09반응형
이번 포스트는 백엔드 경험을 공유한 발표영상들을 정리했다.
if(kakaoAI)2024 day2 시청 및 정리 ... 프론트엔드
이번주에 if(kakaoAI) 2024 발표 영상이 공개됐다.개인적으로 AI 모델링, 서빙, Feature Store보다는 AI 사용하는 거에 관심이 많아 정리는 안 하고 간단하게 보기만 했다. Day2와 Day3 발표에서 관심가는 발
dol9.tistory.com

카카오톡 펑 개발기
PUSH방식과 PULL 방식 소개


PUSH는 필요하지 않은 일을 할 수 있다.
PULL은 생성과정은 빠르지만 피드에 들어가야 할 피드를 찾아야 해서 조회가 느리다.
서비스의 사용패턴은 생성보다 조회 트래픽이 많은 SNS와 유사하다.
97%가 조회 트래픽이고 3%가 생성 트래픽인 카톡 프로필과 비슷하다고 생각했고
그리고 트위터의 인플루언서가 없다는게 PUSH 모델에 힘을 실어줬다. (카톡에 수십만 명을 친구로 둔 사람은 없으니..)
PUSH PULL 피드 구성 대상 모든 조회자 조회하려는 유저 피드 구성 시점 펑 생성 시 펑 조회 시 시간적 특징 생성은 느리지만, 조회가 빠름 생성이 빠르지만, 조회가 느림 공간적 특징 1 : N 1 : 1 피드를 보여주기 위해선 누가 누구에게 어떤 펑을 공개했는지에 대한 정보가 필요한데 이를 공개대상이라고 표현한다.
펑 하나당 조회자 수 만큼 row가 생겨서 샤딩을 적용했고 키는 조회자 id로 했다.


리비젼 개념 도입하기
피드의 변화는 펑을 생성하거나 삭제할 때 달라진다.
두 이벤트가 발생하지 않으면 조회자는 DB접근할 필요 없다.
그래서 서버의 revision과 클라가 갖고 있는 revision을 비교하는 로직을 추가했다. (본거 또 보고?)
펑 생성을 느리게 하는 원인 중 하나는 펑을 공개하는 조회자 수만큼 row 생성하는 로직이 있다.
latency가 느려짐, 시스템 자원 고갈(IO thread, connection pool), 트래픽 폭증할 때 분산도 필요한 문제가 있어서
이를 비동기로 처리하도록 했다.
펑 본문을 DB에 저장하고 "펑id, 공개대상 id"는 MQ에 던져 비동기로 처리한다.


카카오페이는 어떻게 수천만 결제를 처리할까? 우아한 결제 분산락 노하우
잘못된 동시성

분산락
분산된 여러 시스템이 하나의 공유 자원을 안전하게 접근할 수 있도록 사용하는 동기화 메커니즘
AOP 분산락 코드 살펴보기



스프링 AOP 분산락의 불편한 점
- 적용여부 확인이 어려움 - SpEL 문자열로 정의. proxy 객체, public method에만 적용 가능
- 락 장시간 점유로 불리한 성능 - method 내에 락이 필요한 영역과 불필요한 영역이 나눠져 있다.
- Key 파라미터 적용 까다로움 - 첫번째 파라미터로 받고 문자열로 받는다.
- 기능 수정 및 리팩터링 주의 필요 - 리팩토링하다 첫 번째 parameter를 바꾸면 분산락이 적용되지 않거나 잘못된 키로 락이 걸린다.
함수형 프로그래밍을 이용



지연이체 서비스 개발기: 은행 점검 시간 끝나면 송금해 드릴게요!
지연이체 서비스는 이체하려는데 은행 점검 시간이 걸린 경우 점검이 끝나고 가능하도록 이체를 예약하는 서비스다.
사내 공용 메시지 큐를 RabbitMQ에서 Kafka로 정했다.

스케줄러를 늘리는 방식도 생각했지만
그러면 유저가 겹치지 않도록 분기로직이 필요하고
스케줄러가 늘어난 만큼 순간적으로 송금 서버가 받는 트래픽이 증가하여 부하가 발생하므로
스케줄러 늘리는 방식은 적용하지 않았다.

그래서 MQ를 적용했다.
문제 1.
5분마다 스케줄러가 도는데 컨슈머 속도가 느려서 처리 하지 못한 메시지가 생길 수 있고
스케줄러는 DELAY 상태로 있는 송금 건을 다시 MQ에 보낸다.
Consumer에서 송금 실행 전에 송금 건 상태를 체크하는 로직을 적용했지만
아주 낮은 확률로 서로 다른 컨슈머가 처리할 수도 있어 추가 작업이 필요했다.
Redis를 이용한 Global Lock을 이용했다.

User Lock으로 중복 송금은 막았지만 송금 실패가 발생했다.
한 유저가 여러 건의 지연 이체를 등록할 수 있었는데
여러 컨슈머에서 처리하다보면 User Lock으로 인해 한건을 제외한 나머지 건들은 실패 한다.그래서 동일한 유저는 한 컨슈머에서 처리하도록 하기 위해 Kafka record key에 UserId를 지정했다.
짜잔!! New 지연이체 아키텍처

하지만 처리속도가 느려 문제가 발생했다.
하지만 아래와 같이 Zuul Proxy를 이용하여 트래픽을 제어하고 있어서 문제가 생겼을 때 빠르게 롤백할 수 있었다.

실행속도 부스트업 해결
1. 파티션 개수와 동일한 컨슈머 개수
2. 컨슈머에서 Batch Read로 설정해서 컨슈머가 한 번에 다건으로 가져오도록 했다.
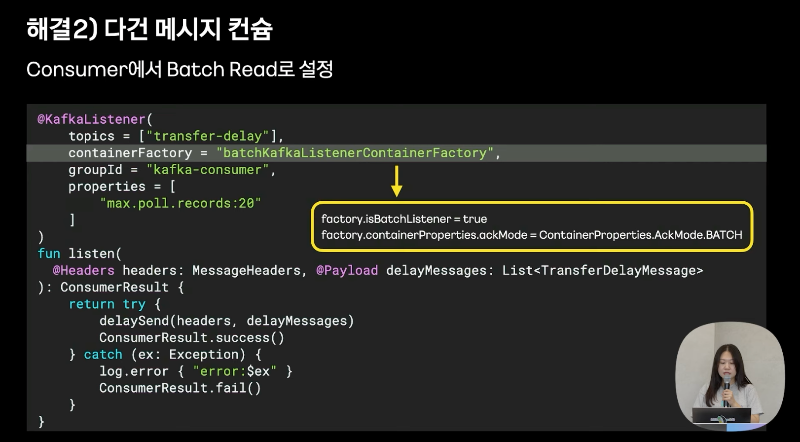
여러 건 가져와도 한건씩 처리하면 실행속도가 크게 달라지지 않았다.
3. Multi thread 처리하도록 했다.

대용량 트래픽 아니면 안 보셔도 됩니다! 선물하기 서비스 캐싱 전략
Cache Stampede.
캐시가 만료될 때 여러 클라이언트가 동시에 동일한 리소스에 접근
동일한 리소스를 동시에 여러 번 캐싱될 수 있음
서버 부하 증가 및 성능 저하 초래
해결 방법
. 캐시 TTL 증가 - 사용자들에게 안 좋은 경험을 줄 수 있다.
. 요청 Lock 증가 - 다른 요청들의 응답 지연 문제가 있다.
. 캐시 웜업 - 별도의 배치를 통해서 많은 트래픽이 발생할 수 있는 데이터를 캐싱 <-- 현재 이 방법 사용
Hybrid Cache

개인화되지 않았고, 수정이 빈번하게 일어나지 않으면서 데이터의 크기가 작고 조회 키 범위가 작은 데이터를 캐싱하자!
각 서버에 로컬 캐시를 활용한다면??
일관성 유지를 위해 Zookeeper의 Watch 기능을 활용했다.
변경 이벤트를 발생할 때 시간값을 이용해 동기화한다.

Auto Cache Warm Up

PER 알고리즘을 사용해 보자.
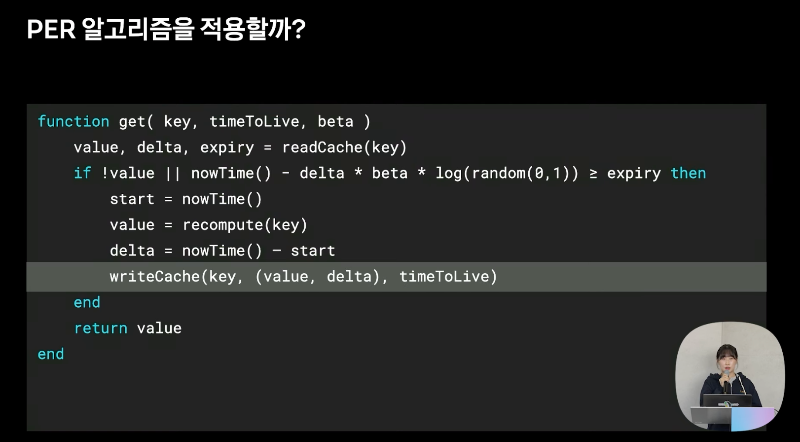
캐시가 만료되기 전 캐시를 갱신해서 Cache stempe 해결가능하지만 적용하지 않았다.
하지만 프로모션 페이지 특성을 고려했을 때 몇 가지 고민 점
1. 캐시 갱신 여부를 캐시 만료되기 전 요청에만 의존한다.
2. 프로모션 페이지는 일정한 갱신시간(delta)을 기대하기 어렵다. 매우 유동적이다.
프로모션만의 특성을 담은 "캐시 웜업 자동화 방식"이 필요하다.
HOT 프로모션을
꾸준히 호출되는 프로모션인 Steady Promotion, 급격하게 트래픽이 증가한 프로모션 Spike Promotion을 분리해 정의했다.

HOT 프로모션을 자동 수집하고 주기적으로 캐시 웜업 기능이 필요했는데 먼저 수집을 설명한다.
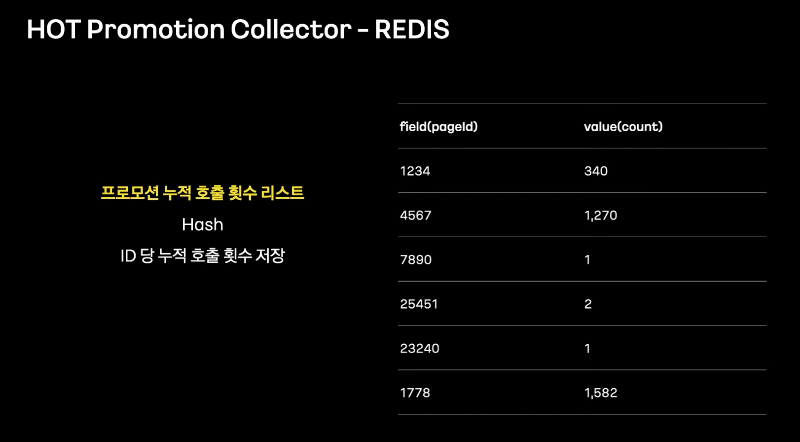
프로모션 페이지의 고유 ID와 최근 호출시간을 기록해서 유저의 선호도를 판단한다.
아래 예를 들면 9월 7일 18시 18분이라고 할 때 HOT 프로모션은 1778이다.

HOT Promotion Collector
Redis의 SortedSet에는 프로모션페이지 ID당 최근 호출된 시간을 저장한다.

Hash key를 시간별(yyyyMMddHH) 지정하고 값에는 프로모션 페이지 ID와 누적 호출 횟수를 저장한다.
HOT Promotion 최종 스코어 계산

Steady Promotion인 경우 누적 횟수 스코어 가중치가 높을 수 있다. 스타벅스 상품권

Spike Promotion인 경우 최근 호출 시간 가중치가 높을 수 있다. 외부채널, 톡채널 프로모션

Promotion ID별 계산 하고 순위를 매긴 후 특정 개수만큼을 HOT Promotion이라고 정의한다.

- 유저가 프로모션 페이지를 요청하면
- Promotion 서버는 Local Storage에 Promotion ID와 호출 횟수를 임시로 저장하고
- 최신 상태가 반영된 리모트 캐시에서 조회 후 유저에게 응답한다.
- 일정 시간이 지나 Local Storage에 있던 데이터를 HOT Promotion Collector에 전송하고
- HOT Promotion Collector은 계산 후 HOT Promotion에 저장한다.

- 특정시간이 되면 배치가 실행되면서 HOT Promotion 조회하고
- 상품 서비스에서 최신 상품 상태를 조회한 뒤
- 캐시에 최신 데이터로 갱신한다.

초단위 Cache Warm UP
캐시 갱신 주기는 1분인데 특정한 경우에는 1분 갱신주기가 길 수 도 있다.
RabbitMQ의 Dead Letter Queue 시스템을 이용하여 1초 주기 갱신이 가능하도록 만들었다.


Cache Stampede를 대응하는 성능향상 전략, PER 알고리즘 구현
반응형