-
Elasticsearch의 개념 살펴보기..(2)아래에서 위로개발하면서/타인글보면서 2021. 8. 30. 08:59
이전 포스트에선 Elasticsearch 개념을 사용하는 측면으로 알아보았다.
이번에는 반대로 Elasticsearch의 주 기능인 검색을 담당하는 Lucene 그리고 이를 관리하기 위한
Elasticsearch의 기능들을 알아본다.
바닥(?)을 알게 되면 Elasticsearch API들을 이해할 때나 문제 해결 시 도움이 될 것이다.
물론 모든 바닥을 알기에는 우리의 시간은 유한하니 나한테 필요한지 아닌지 고민하자 시작하자.https://www.elastic.co/blog/found-elasticsearch-from-the-bottom-up
역색인(Inverted Index)
검색엔진을 처음 배우면 듣는 자료구조다. 바로바로 역색인
입력한 문서에서 필드별로 사용자가 지정한 Analyzer를 적용하여 단어를 추출하고, 단어가 출연한 문서 번호를
값으로 가진다. 문서번호로 검색하면 해당 번호에 해당하는 문서를 결과로 주듯이
(너무 단순화한 감이 있다.) 검색어(Term)로 입력하면 해당 검색어가 포함된 문서를 결과를 주는 방식이다.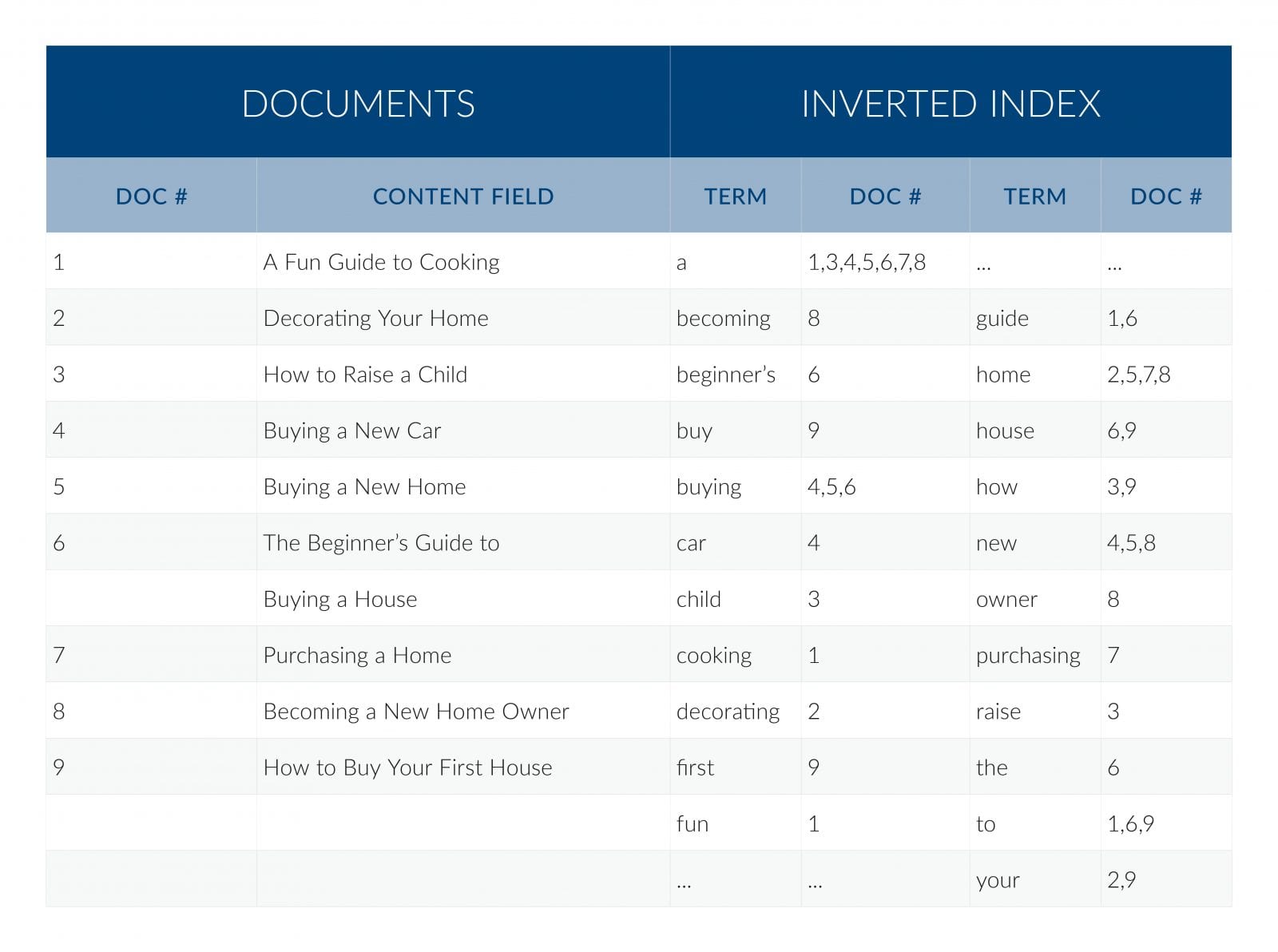
출처: https://lucidworks.com/post/full-text-search-engines-vs-dbms/
MySQL에서 "select doc_id from documents where term like '*house*'" 쿼리를 실행해도
검색엔진에서 house 검색한 결과를 얻는 것 같은데 두 차이는 무엇인가?라는 생각이 들 수도 있다. [1], [2]
사실 내가 처음 검색엔진 접했을 때 사수가 질문한 내용이다.※ 찾다 보니 MySQL에서 FULLTEXT 인덱스 지원한다는 내용을 봤는데 논외로 하자 허허허
성능 문제는 차치하더라도 가장 큰 차이점은 단어를 추출하고 색인, 검색할 때도 검색어를 추출하는 방법이지 않을까 한다.
검색엔진은 형태소 분석, 불용어 처리, 동의어 처리 기능이 있다.
그리고 필드 혹은 단어에 가중치를 줄 수도 있다.Lucene Index
검색 속도와 색인 속도는 반비례 관계이지만 Lucene과 Elasticsearch은 성능 개선을 위한 다양한 방법이 있다.
. 숫자 배열 필드를 가진 문서를 저장할 때 delta-encoding 적용
. Lucene 색인은 immutable 한데 문서 삭제 요청이 오면 실제로 삭제하지 않고 문서 삭제 정보를 관리하는 파일에 기록
. 문서 추가할 때 바로 디스크에 쓰지 않고 memory에 먼저 쓰고 Lucene flush가 실행되면 segment에 기록한다.
※ Elasticsearch에서 flush는 Lucene에서 commit, Elasticsearch에서 refersh는 Lucene에서 flush로 보면 된다.. 역색인 구조에서 정렬은 적합하지 않아 만든 자료형 DocValues. [3]
Lucene segment file
Lucene index는 한 개 이상의 segment로 이루어져 있다.
문서가 계속 추가되면 작은 segment들이 많아지는데 크기가 작은 파일이 많아진다는 건 file descriptor도 증가하고
한방에 할 수 있는데 segment 마다 검색을 수행하면서 검색 성능의 저하가 될 수도 있다.
※ 검색 요청이 올 때 5개 파일에서 검색하는 것과 1개 파일에서 검색하는 것을 상상해보자.
병렬로 하면 차이 없지 않아?라는 생각이 들 수 있지만 컴퓨팅 자원은 무한하지 않다.그래서 Lucene은 주기적으로 작은 segment file 합치는 'merge' 작업을 하는데 다양한 규칙들이 있다. [4]
merge 작업할 때 삭제된 문서는 제외한다.
segment가 합쳐져 새로운 segment가 만들어지면 field/filter cache가 지워지는데 이때 검색 성능 저하 여지가 있는데
Elasticsearch에서는 이를 보완하기 위해 warmup thread 가 있다. 와우!!! [5]Elasticsearch Index
Elasticsearch index는 한 개 이상의 Lucene index로 이루어져 있다.
즉 Elasticsearch shard와 Lucene index에 대응되고 여기서 routing기능이 추가된 게 Elasticsearch index로 봐도 된다.
문서 추가 요청이 오면 coordinator에서 Elasticsearch index의 primary shard가 위치한 노드로 routing 하고
해당 shard에서 색인 처리, 그리고 replica shard에서 transaction_log를 이용하여 복사를 한다.Transactions
Lucene segment 만드는 비용은 꽤 비싸므로 Elasticsearch에서는 transaction log 개념을 도입했다.
Elasticsearch shard 별 transaction log이 존재하는데 노드 상태나 flush 타이밍에 따라 같은 shard라도
transaction log는 다를 수 있다. 동일한 shard여도 refresh, flush 타이밍에 따라 검색이 될 수도 안 될 수도 있다.
동일한 검색 결과를 내주기보다 속도를 선택했다!!!
※ transaction log의 자세한 내용은 이전 포스트에서 썼으니 참고해주세요출처
https://stackoverflow.com/questions/224714/what-is-full-text-search-vs-like ... [1]
https://lucidworks.com/post/full-text-search-engines-vs-dbms/ ... [2]
http://makble.com/how-to-use-lucene-docvalues ... [3]
https://lucene.apache.org/core/7_4_0/core/org/apache/lucene/index/MergePolicy.html ... [4]
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-threadpool.html ... [5]
Elasticsearch의 기본 개념들을 위에서 아래로, 아래에서 위로 알아보았다.
띵언을 봤는데 앞으로 Elasticsearch 기능 알아보기 전에 띵언을 곱씹으며 범위와 깊이를 생각해야겠다.
"All problems in computer science can be solved by another level of indirection." – David J. Wheeler
"If I had an hour to solve a problem and my life depended on the solution, I would spend the first 55 minutes determining the proper question to ask, for once I know the proper question, I could solve the problem in less than 5 minutes." - 아인슈타인(Albert Einstein)