-
Kafka 스키마 관리, Schema Registry개발하면서/코드보면서 2019. 8. 26. 00:56반응형
Why?
Apache Kafka® is a distributed streaming platform.
Apache Kafka 페이지에 들어가면 볼드체로 가장 먼저 보이는 문장입니다.
카프카는 메시지 브로커 역할을 굉장히 잘해주는데요 , 주고받는 메시지의 유효성 검사(?)는 하지 않습니다.
보내면 받은 대로 저장하고 달라면 저장된 데이터를 주는 역할만 하죠.
Consumer 입장에서는 받은 메시지가 어떤 내용인지 알아야 파싱 하고 적절한 로직을 실행할 텐데
Kafka는 이를 보장하지 않으니 Producer, Consumer 개발하는 쪽에서 서로 약속하고 메시지를 주고받아야 합니다.
그래서 csv, xml, json 같은 데이터 포맷을 적용해서 메시지를 주고받습니다. 하지만 이것도 불안한 점이 있습니다.
Producer와 Consumer를 동일한 개인/팀이 관리한다면 그나마 괜찮지만 서로 다른 팀이 관리한다면 아래와 같은
상황이 종종 발생되고 Consumer에서 Parsing 할 때 오류가 발생합니다.
- 공유 없이 필드명이 변경돼서 Produce 됐다. (Phone -> Phone2)
- 공유 없이 특정 필드 데이터 타입이 변경돼서 Produce 됐다. (Integer -> String, Double -> Integer)
- 공유 없이 필드가 삭제돼서 Produce 됐다.
Schema Registry?
Kafka를 이용하여 주고받는 메시지 스키마를 중앙에서 관리하기 위해 나온 프로젝트가 Schema Registry입니다.
Schema Registry는 내부적으로 Avro를 사용하고 RESTful을 이용하여 Avro 스키마를 저장/조회 가능하며
설정에 따라 상위/하위/양쪽 호환성을 보장합니다.
Topic? Schema? Subject?
HTTP endpoint를 보면 Schema와 Subject가 보입니다.
Topic은 Kafka Broker의 토픽을, Schema는 Avro data format를 의미합니다.
하나의 Topic에 하나의 Schema만 produce만 할 수 있지만 여러 schema를 하나의 토픽에 넣고
Consumer에서 분리할 수도 있습니다. [관련 링크]
그래서 Topic과 Schema를 바로 매핑하지 않고 중간에 Subject라는 개념을 두어 Topic과 Schema 간의 의존성을
느슨하게 했습니다.

하나의 토픽에 하나 이상의 Subject, 하나의 Subject에 하나 이상의 Schema version은 특정 subject 내에 Schema version을 의미하고 id는 Schema Registry에서 전역으로 사용되는 값입니다.
version은 Subject 내 사용되는 지역변수, id는 Schema Registry에서 사용하는 전역 변수 정도로 생각하면 될 것 같네요.
간단하게 Schema Registry에서 Schema, Subject 조회하는 API를 살펴보겠습니다.
/subjects
[ "A-value", "B-value", "C-value", "D-value" ]/subjects/A-value/versions
[ 3, 5, 7, 9 ]/subject/A-value/versions/7
{ "subject": "A-value", "version": 7, "id": 72, "schema": "{\"type\":\"record\",\"name\......}" }/schema/ids/72
{ "schema": "{\"type\":\"record\",\"name\......}" }※ Protobuf, Thrift, ORC 등 괜찮은 serialization 오픈소스도 있는데 왜 Avro일까?
JSON 스키마 정의가 가능하고 압축률이 좋고 빠르다.. 를 얘기하지만 제가 생각하기엔
앞의 이유보다 LinkedIn 내부에서 데이터 파이프라인의 표준을 Avro로 썼는데 이게 이어진 게 아닐까 생각해봅니다ㅎㅎ

https://engineering.linkedin.com/blog/2016/04/kafka-ecosystem-at-linkedin Schema Registry 적용 시 장/단점
schema를 사용할 때 생기는 장점
주고받는 메시지의 스키마 관리 용이
- Schema 호환성만 유지된다면 특정 토픽에 여러 버전의 스키마 데이터를 Produce/Consume 가능
반복되는 값이 많다면 압축률 상승. (약간의 CPU 연산 사용)
schema를 사용할 때 생기는 단점고려할게 많아 "초기에는" 사용하기 불편합니다. Json으로 했으면 금방(?) 끝났을 것 같은데 이해하고 적용하는데
걸린 시간이 주마등처럼 스쳐 지나가네요...
Schema Registry 어떻게 사용되나?
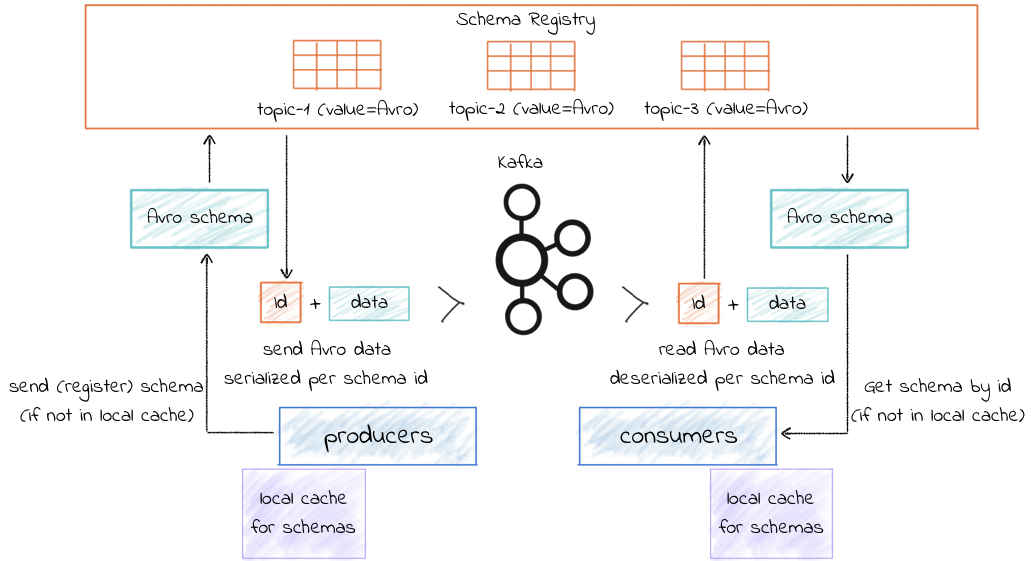
https://docs.confluent.io/current/schema-registry/index.html 출처: https://docs.confluent.io/current/_images/schema-registry-and-kafka.png
Producer 입장
※ props.put(AbstractKafkaAvroSerDeConfig.AUTO_REGISTER_SCHEMAS, true); 인 경우 새로운 Schema가 등록되면
자동으로 Schema Registry에 등록됩니다. Production 환경에서는 false로 하는 걸 추천하네요. 아래 예제는 true인 경우로 진행
1. 보내려는 Schema가 local cache에 존재하지 않으면 Schema Registry에 전송
2. 이미 Schema Registry에 존재하는 Schema 인 경우 id, version, Schema 정보를 내려주고,
새로운 Schema 라면 Schema Registry에 등록하고 id, version, Schema 정보를 내려줍니다. local cache 저장.
2-1. subjects 호환성 설정에 어긋나는 Schema를 전송하는 경우 오류 발생합니다.!!
3. Schema 정보를 이용해 key/value를 serialize 하고 Schema Registry 전용 형식으로 맞추고 Kafka 전송.
Consumer 입장
1. Kafka로부터 받은 메시지에서 id 값을 가져옵니다. 해당 id로 등록된 정보가 local cache에 없으면 Schema Registry에 요청
2. Schema Registry로부터 id, version, schema 정보를 내려받습니다. local cache에 저장
3. 1번에서 가져온 id에 맞는 Schema로 deserialize를 진행합니다.
아래 그림은 value만 Avro serialize인 경우

Schema Name Strategy
위에서 살펴본 Producer의 설정 값 중 AUTO_REGISTER_SCHEMAS를 true로 하면 새로운 Schema 전송 시 자동으로 등록이
되는데 이때 subject명을 정하는 방법이 3가지가 있습니다.
# TopicNameStrategy public String subjectName(String topic, boolean isKey, Schema schema) { return isKey ? topic + "-key" : topic + "-value"; } # RecordNameStrategy public String subjectName(String topic, boolean isKey, Schema schema) { if (schema == null || schema.getType() == Schema.Type.NULL) { return null; } # getRecordName 함수는 Avro record의 fullname을 가져오는 함수입니다. return getRecordName(schema, isKey); } # TopicRecordNameStrategy public String subjectName(String topic, boolean isKey, Schema schema) { if (schema == null || schema.getType() == Schema.Type.NULL) { return null; } return topic + "-" + getRecordName(schema, isKey); }호환성
A라는 subject에 X-2, X-1, X 버전의 Schema가 있다고 가정하겠습니다. X가 가장 최신이고 X-2가 가장 오래된 Schema입니다.
BACKWARD Compatibility
subject 생성 시 default 값입니다.
X 버전으로 Consumer가 구동됐을 때 X는 물론이고 X-1로 Serialize 된 메시지를 읽을 수 있는 걸 뜻합니다.
중요한 건 X-2 <-> X-1, X-1 <-> X를 보장한다고 해서 X-2 <-> X를 보장하지 않을 수도 있습니다.
확실히 보장하기 위해선 BACKWARD_TRANSITIVE로 subject를 생성해야 합니다.
FORWARD CompatibilityX Schema로 Produce 된 메시지를 X는 물론이고 X-1로 구동된 Consumer가 읽을 수 있는 걸 뜻합니다.
위에서도 본 것처럼 X <-> X-2를 보장하기 위해선 FORWARD_TRASITIVE로 subject를 생성해야 합니다.
FULL, FULL_TRASITIVE, NONE (자세한 설명은 생략합니다 ㅎ)아래 링크에 Avro 호환성 관련 예제와 함께 잘 설명되었습니다. 참고하세요
http://dekarlab.de/wp/?p=489
막상 이렇게 정리해도 사용할 때마다 헷갈립니다...AvroCompatibilityTest.java 참고해서 프로젝트에서 사용되는 Avro data format 호환성 체크하는 테스트 코드 작성하는게
맘 편하고 좋은 것 같습니다.마지막으로 Schema Registry 적용을 검토하시는 분들에게 긍정적인 기운을 불어넣는 짤막한 글 스샷을 첨부하고 마무리 짓겠습니다.

https://www.confluent.io/blog/schema-registry-kafka-stream-processing-yes-virginia-you-really-need-one/ 참고 자료
https://engineering.linkedin.com/blog/2016/04/kafka-ecosystem-at-linkedinhttps://medium.com/@stephane.maarek/introduction-to-schemas-in-apache-kafka-with-the-confluent-schema-registry-3bf55e401321
https://www.confluent.io/blog/avro-kafka-data/
https://www.confluent.io/blog/schemas-contracts-compatibility
https://www.confluent.io/blog/put-several-event-types-kafka-topic/
http://cloudurable.com/blog/kafka-avro-schema-registry/index.html
반응형